How incrementality testing proves impact and sharpens growth


.png)
CPIs rose ~30% globally last year.
So growth teams are doing the rational thing: they're putting more budget towards reactivating the users they already have.
The logic checks out: a lapsed user already knows your app, already cleared the install friction, and already showed enough intent to download in the first place.
But as retargeting spend has risen, so too has the skepticism: would these users have come back anyway?
It's a fair question. Standard attribution can tell you what converted after the ad fired. It cannot tell you what would have converted without it. The retargeted user who re-installs the day after seeing your ad gets credited to the campaign, regardless of whether the ad was the reason or whether they were already on their way back.
This is the gap that incrementality testing closes.
Investing in retargeting is the most efficient way to maximize your growth budget. But if you want to prove the impact of your retargeting efforts, incrementality testing is the way. It's also the sharpest tool available for understanding which inventory, segments, and buying behaviors are driving incremental lift, so you can double down on the strategies that work.
Incrementality testing borrows its core mechanic from clinical research, but the application is built for ads.
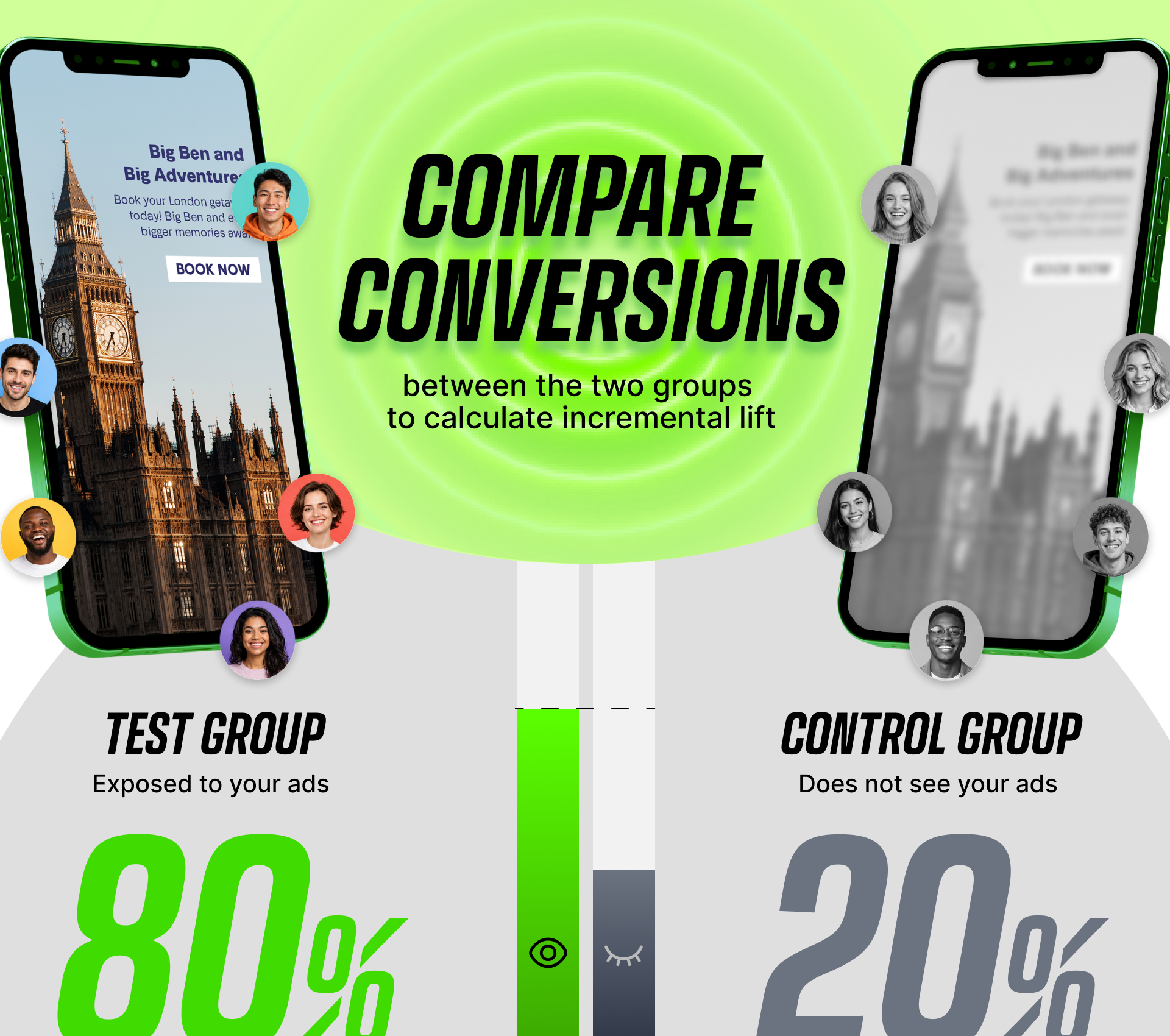
You take an audience of users who all meet the same criteria. Lapsed payers from the last 30 days, dormant users who haven't opened the app in 60+ days, whatever segment you want to put under the microscope. You randomly split that audience into two groups:
The held-out/control group exists for one reason: to show you what would have happened if you'd done nothing. Same users, same time window, same behavior patterns, same everything. The only variable that changes between the two groups is whether they got served your ads.
At the end of the test, you measure both groups on the same outcome. Re-engagement rate. Revenue per user. Whatever the campaign was supposed to drive.
If the test group beats the control group, the difference between them is your incremental lift. That's the impact your ads caused.
This is the read that standard attribution can’t give you; because it has no way of constructing the counterfactual: the version of reality where the ad didn't run. The control group is the counterfactual, built deliberately, and held apart from the campaign so the comparison stays clean.
A trustworthy incrementality test is only as good as the discipline behind it. Three principles separate a real lift study from a test that's just telling you what you wanted to hear:
When all three hold, the resulting number is causal: this is the lift your ads drove.
RZR’s Incrementality Framework is one standardized, holdout-based methodology, applied the same way to every client, and wired into how we optimize, report, and run our reporting. Four principles hold it together.
Every device in the audience pool is assigned to either the test or control group using deterministic MD5 hash binning on its IDFV (Apple's Identifier for Vendor).
Here's how it works:
No randomness at bid time. No possibility of a user drifting between groups. No chance of a single device appearing in both arms of the study. The assignment is fixed before the test begins, and RZR shares the full IDFV list with bucket assignments so the client can audit every device independently.
This is what removes the most common form of test contamination: users who would have been in the control group accidentally getting served impressions because the assignment logic was probabilistic instead of deterministic.
In any random split, one group can end up slightly heavier on power users by pure chance. Run a single phase and that imbalance bakes into the result.
RZR's test runs in two phases:
Any random imbalance from Phase 1 gets averaged out by Phase 2. This is the cleanest available defense against the most common form of incrementality result contamination, and it is the reason a 31-day RZR test produces a more defensible number than a single-pass holdout of the same duration.
Incrementality results are only trustworthy if the underlying impressions are real. Resold inventory, duplicate impressions, and non-transparent supply paths inflate baseline reach without driving genuine engagement, which distorts the comparison in both directions.
What keeps the test clean:
RZR's match rate is one of the highest in the industry. The reason is structural: we own the infrastructure. 4 data centers, our own NVIDIA GPU cluster, 6M queries per second, 220B auctions per day. We see more of the open internet than almost anyone, which means more of your test group is actually exposed to ads during the test window. Bigger test pool, sharper lift signal, cleaner number at the end.
Within 5 business days of test close, RZR delivers a full results package built for independent verification:
Below are two examples of RZR’s Incrementality Framework in action, and what the results told the two mobile game publishers about their retargeting spend.
Paxie Games, a casual gaming studio with an IAA and IAP monetization mix, wanted statistical proof that their Android retargeting spend in the U.S. was driving genuine lift. RZR built custom audiences split by monetization behavior (IAA watchers vs. IAP buyers), ran each cohort through its own optimization model, and measured results against a 20% control group with Agresti-Coull confidence intervals.
The lift was significant:
The U.S. result became the benchmark. Paxie used it to scale retargeting into the UK, France, Germany, Canada, Australia, Japan, and Austria, increased retargeting spend by 50%, and named RZR their exclusive retargeting partner.
FOMO Games had scale with Traffic Escape, with strong DAUs and a large churned user base. The growth team wanted to know whether retargeting could bring lapsed users back, and whether the return was incremental or just re-attribution. RZR ran the test across iOS and Android, split by payer and non-payer cohorts, with an 80/20 test/control split over three weeks.
The results:
The test confirmed that IAA-heavy titles can unlock meaningful value from lapsed users, and it gave FOMO the confidence to scale retargeting as a long-term growth lever rather than a tactical experiment.
Run RZR’s Incrementality Framework on a segment or campaign, get a defensible lift number in 31 days, and scale what's working.



Get cutting-edge insights on retention-led growth straight to your inbox.

